写在前面
最近看了leetcuda 的 softmax kernel, 发现里面用到了很多的__shfl 开头的内部函数, 而不是像之前看的书中提到的用两步__syncthreads() . 自测发现效果要比直接归约快不少. 于是学习一下这个函数.
ref:
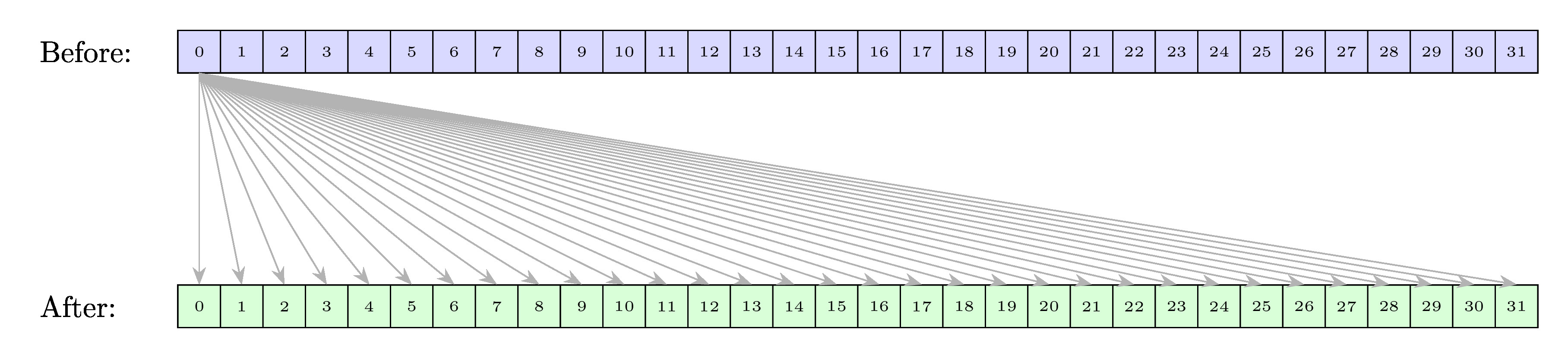
内部函数 __shfl_sync() 允许 warp 中的线程之间交换变量,而无需使用共享内存。交换同时发生在 warp 中的所有活动线程(使用 mask 指定),根据数据类型移动每个线程 或 个字节的数据。
warp 中的线程称为通道(lanes),并且每个通道具有介于 0 和 warpSize-1(包括)之间的索引,称之为通道 ID。当前支持四种源通道(source-lane)寻址模式:
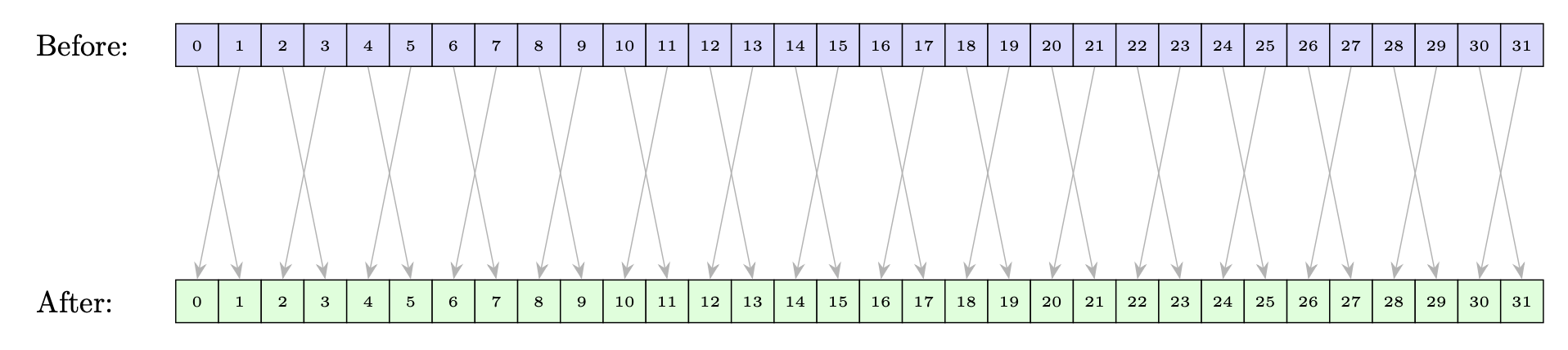
__shfl_sync():从索引通道直接复制。__shfl_up_sync():从相对于调用者 ID 较低的通道复制。__shfl_down_sync():从相对于调用者 ID 较高的通道复制。__shfl_xor_sync():基于自身通道 ID 的按位异或(XOR)从通道复制。
线程只能从另一个参与执行 __shfl_sync() 命令的活动线程读取数据。如果目标线程处于非活动状态,则检索到的值未定义。
__shfl_sync
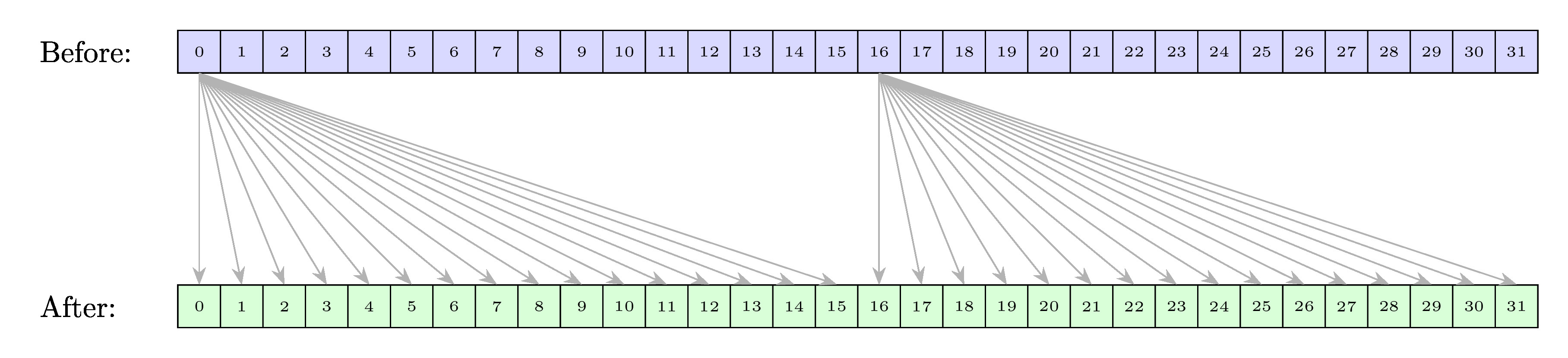
__shfl_up_sync
__shfl_xor_sync
归约函数:一次__syncthreads()