写在前面
一般来说, 如果要拉取一套线上资源. 需要这样
## 线上
nohup python3 -m http.server 40091 &> /dev/null & ## 如果没有写权限.
nohup python -m SimpleHTTPServer 40091 &> /dev/null & ## 如果没有 python3
## 本地
wget --quiet -m -np -nH -R index.html hostname:40091/{bin,conf,data,shared_lib}
但是如果线上资源中已经有了 index.html(可能是之前上线时候忘记删掉了. 但是后续又新增了文件. 这就导致拉取文件缺失了.
核心问题在 python 的 httpserver 源码
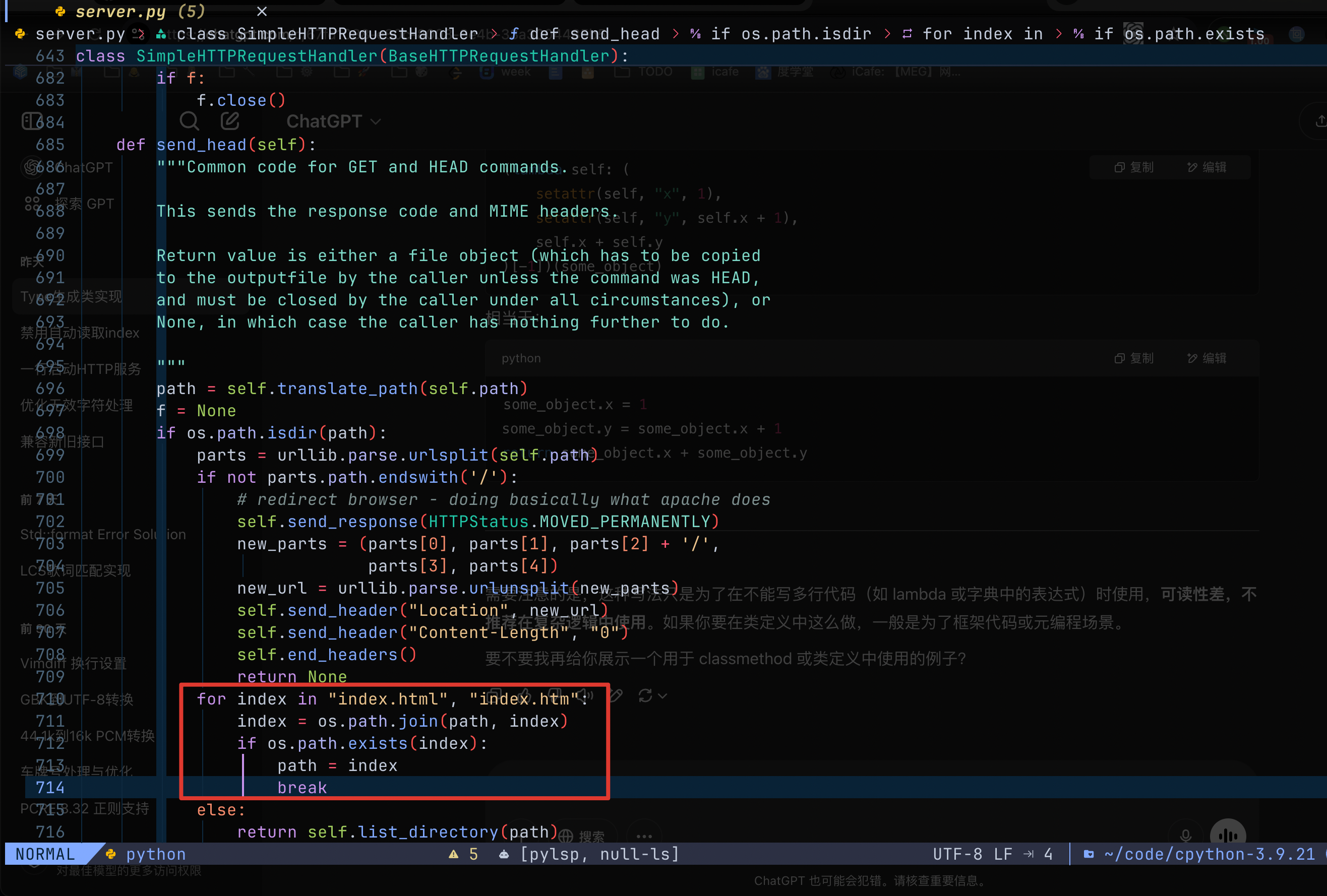
那么怎么解决呢?
可以这样写
from http.server import test, SimpleHTTPRequestHandler as RH
import os
class NoIndexHandler(RH):
def send_head(self):
path = self.translate_path(self.path)
if os.path.isdir(path): # 是路径
if not self.path.endswith('/'): # 不以/结尾
self.send_response(301) # 永久重定向
self.send_header("Location", self.path + '/')
self.send_header("Content-Length", "0")
self.end_headers()
return None
return self.list_directory(path) # 直接列出, 而不读取 index.html
return super().send_head() # 如果是文件, 执行父类的逻辑
test(HandlerClass=NoIndexHandler, port=40091) # 用新写的类+端口
一行命令(用了 type+lambda)
python3 -c "from http.server import test, SimpleHTTPRequestHandler as RH;import os;test(HandlerClass=type('H',(RH,), { 'send_head': lambda self:( (self.send_response(301), self.send_header('Location', self.path + '/'), self.send_header('Content-Length', '0'), self.end_headers(), None)[-1] if os.path.isdir(self.translate_path(self.path)) and not self.path.endswith('/') else self.list_directory(self.translate_path(self.path)) if os.path.isdir(self.translate_path(self.path)) else super(type(self), self).send_head() ) }), port=40091)"
线上实例的 python3.4 也是支持的
nohup python3 -c "from http.server import test, SimpleHTTPRequestHandler as RH;import os;test(HandlerClass=type('H',(RH,), { 'send_head': lambda self:( (self.send_response(301), self.send_header('Location', self.path + '/'), self.send_header('Content-Length', '0'), self.end_headers(), None)[-1] if os.path.isdir(self.translate_path(self.path)) and not self.path.endswith('/') else self.list_directory(self.translate_path(self.path)) if os.path.isdir(self.translate_path(self.path)) else super(type(self), self).send_head() ) }), port=40091)" &>/dev/null &
对于 python2
import os,BaseHTTPServer
from SimpleHTTPServer import SimpleHTTPRequestHandler as SH
class NoIndexHandler(SH):
def send_head(self):
path = self.translate_path(self.path)
if os.path.isdir(path): # 判断是否为目录
if not self.path.endswith('/'): # 如果路径不以 / 结尾
self.send_response(301) # 返回永久重定向
self.send_header("Location", self.path + '/')
self.send_header("Content-Length", "0")
self.end_headers()
return None
return self.list_directory(path) # 直接列出目录内容,而不读取 index.html
return SH.send_head(self) # 调用父类方法处理文件
BaseHTTPServer.HTTPServer(('', 40091), NoIndexHandler).serve_forever()
nohup python -c "import os,BaseHTTPServer; from SimpleHTTPServer import SimpleHTTPRequestHandler as SH; exec('''class H(SH):\n def send_head(s):\n p=s.translate_path(s.path)\n return s.list_directory(p) if os.path.isdir(p) and s.path.endswith('/') else SH.send_head(s) if not os.path.isdir(p) else (s.send_response(301),s.send_header('Location',s.path+'/'),s.send_header('Content-Length','0'),s.end_headers())[3]'''); BaseHTTPServer.HTTPServer(('',40091),H).serve_forever()" &>/dev/null &
wget 常见错误码汇总
Wget may return one of several error codes if it encounters problems.
0 No problems occurred.
1 Generic error code.
2 Parse error---for instance, when parsing command-line options, the .wgetrc or .netrc...
3 File I/O error.
4 Network failure.
5 SSL verification failure.
6 Username/password authentication failure.
7 Protocol errors.
8 Server issued an error response.
遇到下不下来的情况可以加上--cut-dir=1.
例如我要下载线上的资源. 直接执行
wget --quiet -m -np -nH -R index.html example.com:40091/{bin,conf,data,shared_lib}
data 目录下不下来, 变成一个文件了, 此时可以这样
mkdir data && cd data && wget --quiet --cut-dir=1 -m -np -nH -R index.html example.com:40091/data